| MCformer |
| A transformer-based Modulation Classification Model |





|
| MCformer |
| A transformer-based Modulation Classification Model |
|
|
In this research, my friend Swayambhoo and I implemented a novel Transformer-based deep neural network for the automatic modulation classification task of complex-valued raw radio signals. The model—called MCformer—leverages a convolutional layer along with self-attention based encoder layers (BERT) to efficiently exploit temporal correlations between the embeddings produced by the convolutional layer. MCformer provides state of the art classification accuracy at all signal-to-noise ratios in the RadioML2016.10b data-set with significantly less number of parameters which is critical for fast and energy-efficient operation. Our paper was presented in IEEE GLOBECOM 2021 conference.
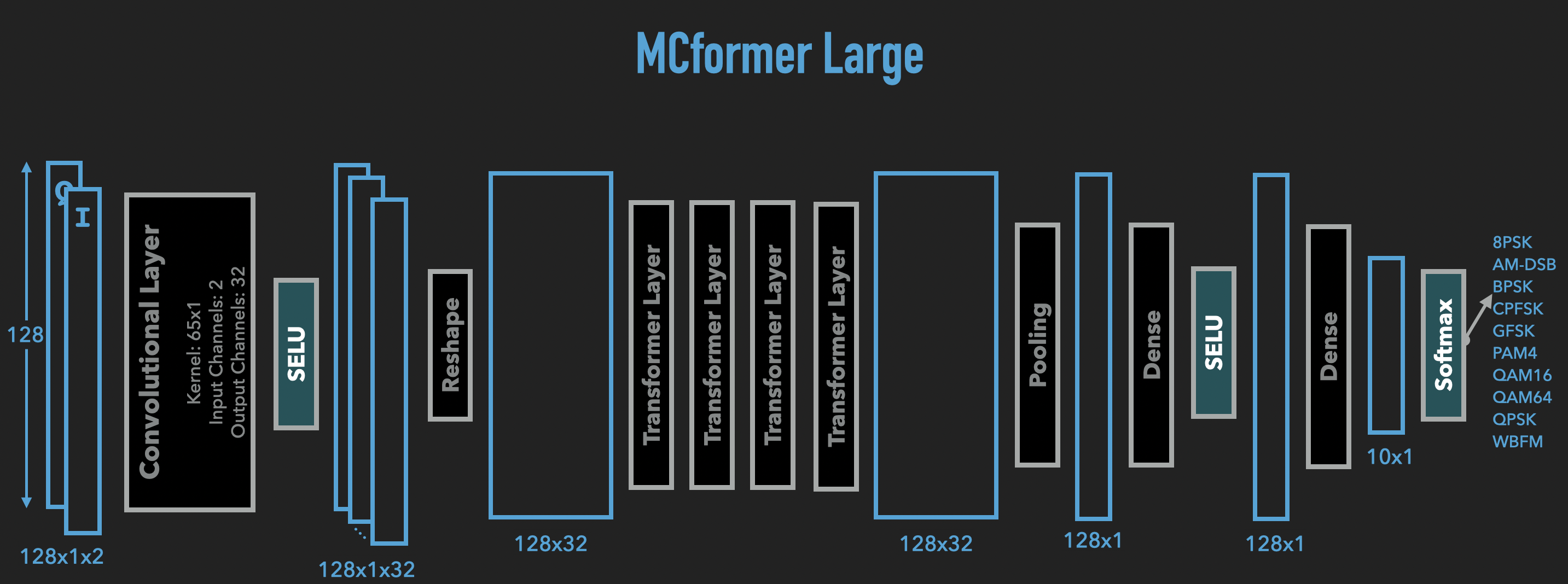
The following diagram shows the MCformer model structure. The RadioML input data are formatted as 128x1x2 tensors. These
tensors are fed to the embedding layers which are made up of a convolutional layer, SELU activation function, and reshaping. The
output of embedding layers is fed to 4 back to back BERT layers. The output of last layer is another 128 by 32 matrix.
Then we apply a pooling operation that keeps the first 4 vectors and flattens it to a vector of size 128. This vector is then
fed to 2 back to back fully connected layers and a softmax activation function. The output is a 10-dimensional vector giving
the probability distribution for 10 possible modulation types. A Fireball implementation
of this model is available here.
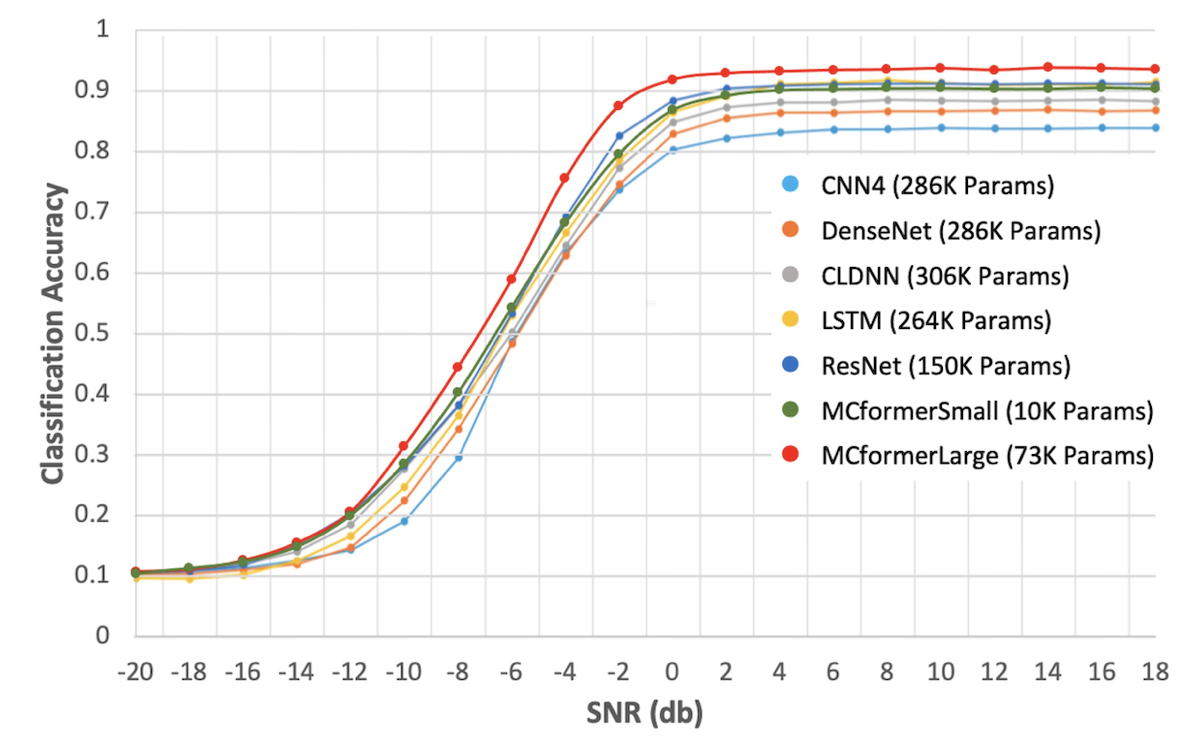
The following diagram compares the performance of MCformer (Large and Small) with 5 baseline models. As you can see
MCformer Large outperforms all baseline models at all SNR values while using significantly less network parameters. Also
performance of MCformer small with just over 10 thousand parameters is comparable with the best baseline models ResNet and
LSTM with about 15 and 26 times more network parameters.
The following video explains the experiments and the results of this research. It was prepared for the IEEE GLOBECOM 2021 conference.